Sub-Agents vs Agent Teams: Stop Making One Agent Do Everything
How to split work across multiple AI agents, when each approach actually makes sense, and how to set them up from scratch.

I ran a single Claude Code session for three hours last week. By the end, it was summarizing its own summaries, mixing up file paths from earlier in the conversation, and giving me suggestions that sounded confident but were slightly wrong in ways I almost missed.
That moment is the reason multi-agent systems exist.
Not because one agent is dumb. Because one agent doing too many things eventually drowns in its own context. Every file it reads, every test it runs, every search result it pulls in... all of that stays in memory. And after a while, the signal-to-noise ratio drops and you start getting output that looks right but isn’t.
The fix isn’t a better prompt. It’s a better architecture.
Claude gives you two ways to split work across multiple agents: sub-agents and agent teams. They solve different problems, they cost different amounts, and picking the wrong one will either waste your money or waste your time.
Here’s how they actually work, when to use each, and how to set them up from scratch.
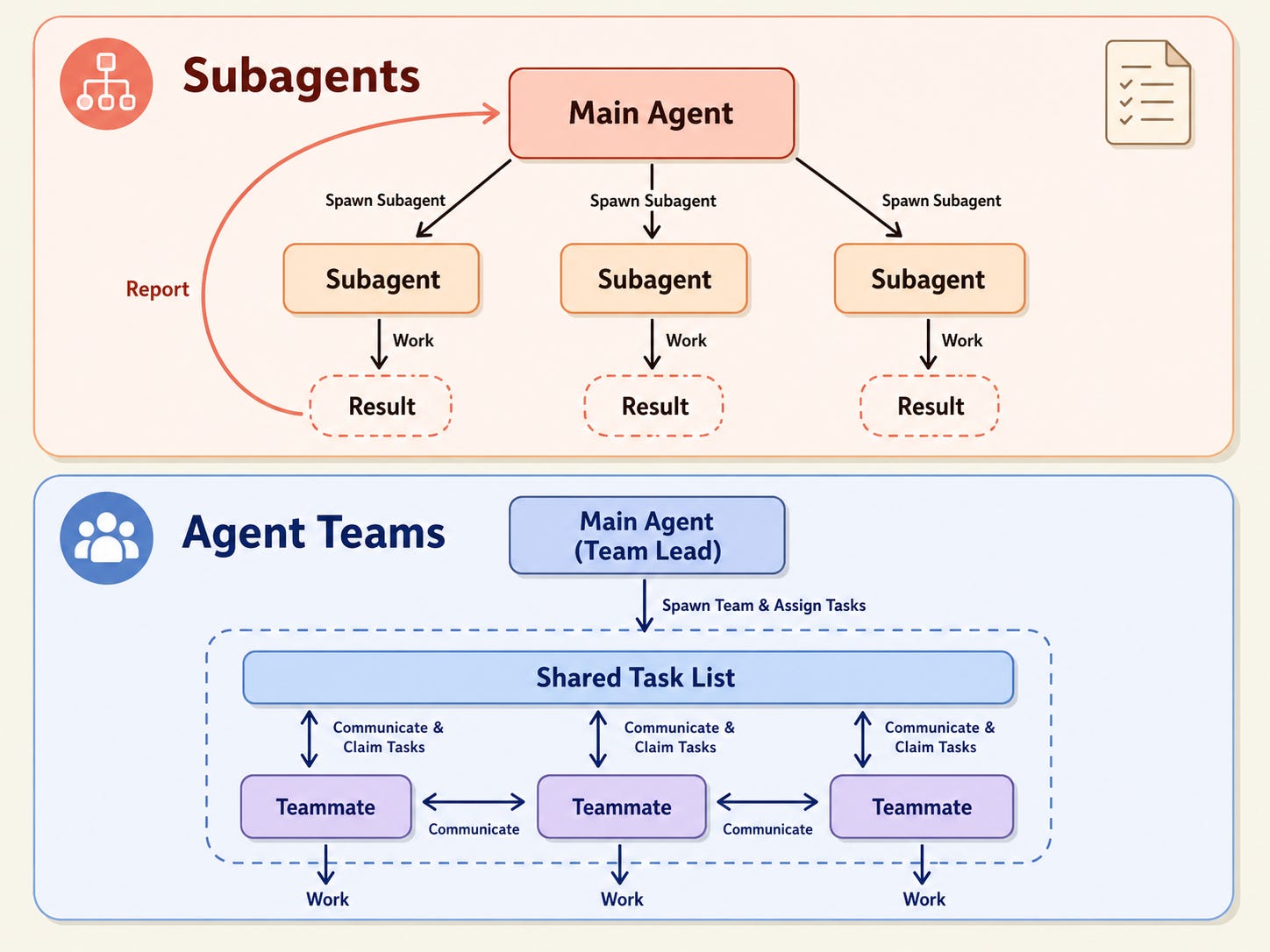
The Problem With Doing Everything in One Thread
Picture this. You ask Claude Code to review your codebase for security issues, refactor a module, write tests, and update the docs. All in one session.
By task three, the context window is packed with grep results, file contents, and reasoning chains from earlier tasks. The test-writing step starts getting influenced by the security review output. The docs update references code that was already refactored. Things start to blur.
This is called context pollution. The agent isn’t broken. It’s just carrying too much baggage from previous steps, and that baggage shapes every new response in subtle, unhelpful ways.
The solution is isolation. Give each task its own clean workspace. Let it do its thing. Return just the result. Keep the main thread clean.
That’s exactly what sub-agents do.
